

Two Key problems that ails Bayesian MMM
Multicollinearity and Bad Priors are the biggest Achilles heel of Bayesian MMM

The Bayesian vs Frequentist debate is an old one. Many would opine that one should take horses for courses approach and that one should not be dogmatic about any one method.
However, it is also seen that for many mission critical processes, Frequentist methods are preferred over Bayesian methods.
Is Marketing mission critical?
Marketing may not be as mission critical as clinical trials domain. However, brands invest real dollars in marketing. Brands hence would want to know if their dollars are getting invested in the most appropriate marketing channels or not. Marketing Mix Modeling answers this very question.
Should Marketers care about Bayesian MMM vs Frequentist MMM Debate?
Yes. Marketers absolutely should care about Bayesian MMM vs Frequentist MMM debate because one method overwhelmingly gives erroneous results. That method is Bayesian MMM.
Highlighting the two main shortcomings of Bayesian MMM
Bad Priors
Bayesian methods hinges on priors. However priors also exacerbate uncertainty.
There are two kinds of uncertainties Aleatoric and Epistemic.
Aleatoric uncertainty: It is the inherent uncertainty present in the data or the model. We generally can't do anything about Aleatoric uncertainty because well it is inherent. One could think of it as some kind of stochastic process.
Epistemic uncertainty: Epistemic uncertainty is caused because of lack of knowledge. Good knowledge infused into the model generally reduces epistemic uncertainty. Examples include model assumptions or in case of Bayesian framework - The Priors.
But here is the catch.
In the Bayesian framework, a bad prior or uninformative prior increases the Epistemic uncertainty.
And as a whole the uncertainty (Aleatoric + Epistemic) of the system just gets exacerbated !
Multicollinearity
Many Bayesian MMM vendors proclaim that Bayesian methods are somehow good at handling multicollinearity. This is simple not true and I will illustrate why.
Multicollinearity is a information redundancy problem and Bayesian methodology can't magically solve it.
Rather the problem becomes worse in case of Bayesian MMM because your posterior distribution keeps getting wide as you have more multicollinearity.
What this means in layman terms?
Lets take an analogy:
Imagine you are on a search party to track down your pet dog that got lost in woods.
You can hear your dog barking and you set up a search radius of say 1km.
But then you also hear another dog (similar to your pet dog) barking in the woods in another direction.
Now you think of expanding your radius by another 1 km.
You see that your search of truth (or your pet dog) got much much difficult because there are same kind of barking noises (signals).
This is what happens in Bayesian MMM too. As you have multicollinearity, your posterior distribution keeps getting wide and you have no clue where the 'true' value lies.
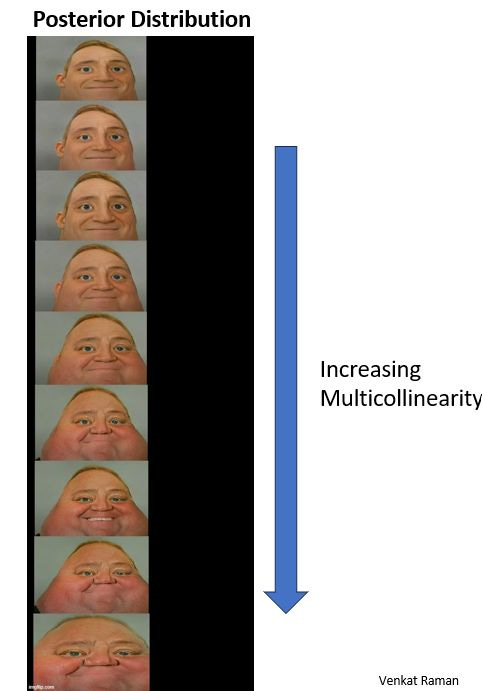
Richard McElreath in his book statistical rethinking highlights the same issue. See image below

The most expensive ‘I don’t know ‘ bill ever footed
It is clear that Bayesian MMM is an ineffective solution compared to frequentist MMM. Multicollinearity in MMM is always a given. Bayesian MMM methods often provide no clear answer when there is even moderate multicollinearity. Bayesian MMM vendors hence shrug their shoulders and say ‘we don’t know’. As a client, adopting Bayesian MMM means footing an expensive fees only to get the answer from the vendor “I don’t know”.
The readers can find below various other articles on why Frequentist MMM are better:
Which technique provides for greater manipulation in MMM - Bayesian or Frequentist?
Bayesian Marketing Mix Modeling's Stating the obvious problem
Hey Venkat, Thanks for sharing. I understand your point on priors, but i am not fully sure if 'multi-collinearity' is a bigger problem in Bayesian. In the graph you shared from 'Statistical Rethinking' book, the 'std deviation' of posterior distribution increases significantly only after correlation exceeds 0.6 or so. However, in my experience i have never seen correlations between 'features' exceed 0.5 (in worst case). So, i am genuinely curious to know if this is a problem. (or if you have seen correlations exceeding 0.6 in your experience?) Also, what is the right 'standard deviation' that we should aim for ? My intent is just to learn and I would love your perspective on this.
Thank you
Ravi (i work as an Analytics Director in a CPG company)