

Is your MMM model accurate or precise?
Don't conflate precision of your MMM model with accuracy


Did the above question confuse you ? If yes, let me first explain the difference between the two.
🎯 Precision vs Accuracy
Let's take an example to drive home the point.
Imagine you are standing on a weighing scale.
The weighing scale is faulty and inflates the actual weight of a person by 1 kg (2.2 pounds).
Now a person with actual weight of 75 kg (165 pounds) uses the weighing scale. The scale shows his weight as 76 kg (167 pounds).
Each time the person uses the weighing scale, the scale shows the weight as 76 kg. Does the scale showing 76kg each time make it accurate ? NO.
Each time, the weighing scale is 'Precise' but not 'Accurate'.
It would have been accurate had it shown the weight of the person as 75kg.
🎯 Is your MMM model accurate or precise?
Now coming to the main topic of our post, MMM vendors (both frequentist & Bayesian) can easily succumb to conflating precision with accuracy.
There is tendency in MMM to expect to see the same contribution numbers and ROI numbers in each iteration of the model.
This is not a wrong expectation to have if you have honed in on the ground truth. A well specified model should theoretically hone in on the ground truth each time.
But the million dollar question is - Have you honed in on the ground truth?
Be it MMM or any ML model there are two ways to know if you have got to the truth - Calibration and Validation
Calibration involves considering the data at hand (as ground truth) and then tweaking your model to give estimates as close or equal to the data at hand. This is also known as gauging for goodness of fit.
But the problem with calibration is we don't know what could happen in the future. Our only hope is that if our model is well calibrated and has good goodness of fit, then perhaps it will also do well on future unseen data.
If your model performs well on future data, then your model is also said to be validated.
The big issue
MMM as a industry has been using inefficient calibration and validation mechanisms which leads to mistaking precision for accuracy.
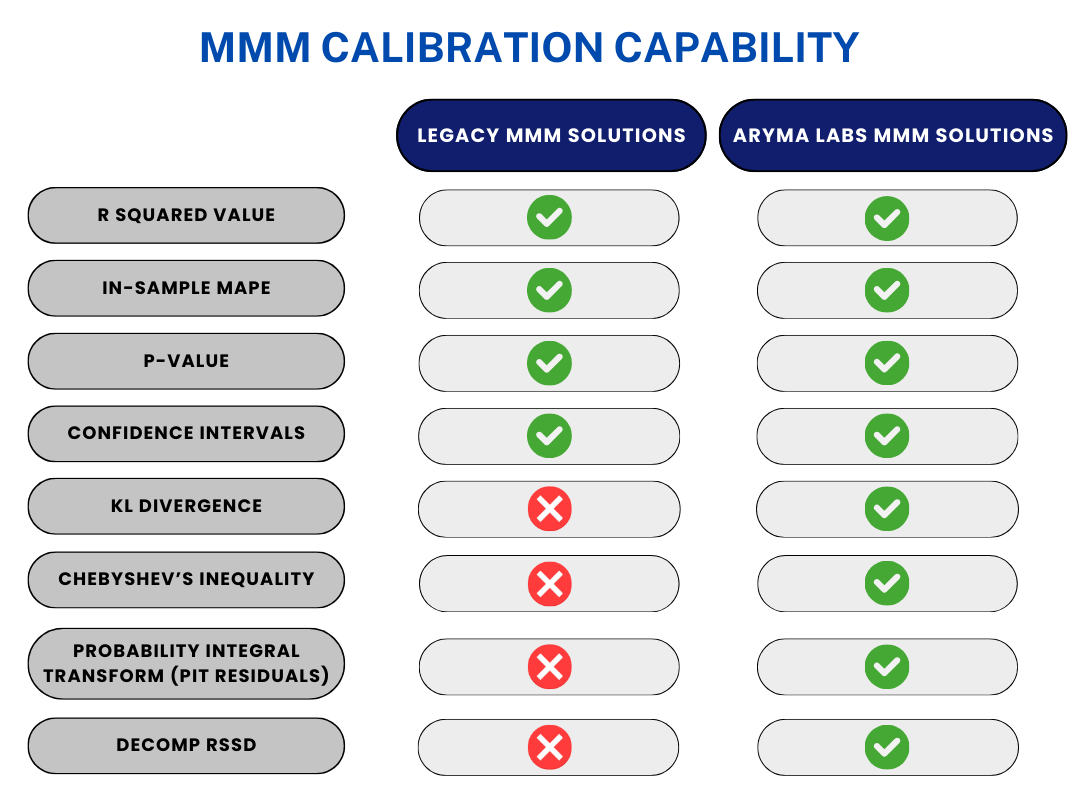
For calibration - it has been just R squared, in-sample MAPE, P-value, CI
and
For Validation it has been out sample MAPE/RMSE.
To avoid conflating precision with accuracy in MMM, we at Aryma Labs have invented newer ways of calibration and validation.
For calibration we use KL Divergence, Chebyshev's Inequality and PIT residuals.
For Validation we use causal experiments - DID, Regression Discontinuity, Propensity scores.
Check out our research papers on the above topic in resources section.
Resources:
Investigation Of Marketing Mix Models’ Business Error Using KL Divergence And Chebyshev’s Inequality
https://www.arymalabs.com/investigation-of-marketing-mix-models-business-error-using-kl-divergence-and-chebyshevs-inequality/
Proving Efficacy Of MMM Through Difference In Difference (DID)
https://www.arymalabs.com/proving-efficacy-of-mmm-through-difference-in-difference-did/
Calibrating Marketing Mix Models through Probability Integral Transform (PIT) residuals
https://www.techrxiv.org/users/778033/articles/941571-calibrating-marketing-mix-models-through-probability-integral-transform-pit-residuals
Thanks for reading. See you all next week with some more insightful content.
For consulting and help with MMM implementation, Click here
Stay tuned for more articles on MMM.
 | A guest post by
|