

Is there a peeking problem in MMM?
Calibrating MMM models via experiments is a form of Peeking


The peeking problem in experimentation occurs when experimenters prematurely examine test results before reaching the predetermined sample size or statistical significance threshold.
Peeking can lead to :
1) Inflation of Type 1 error (False Positives)
2) Reduced Statistical Power
3 Inaccurate insights and interpretation
The illustration shows a simulation of AA tests. One can see that at the point of stopping (peeking) most experiments have statistically significant results.
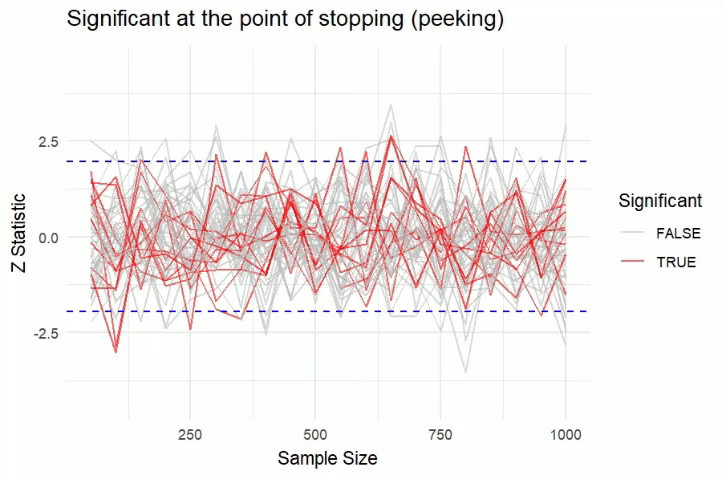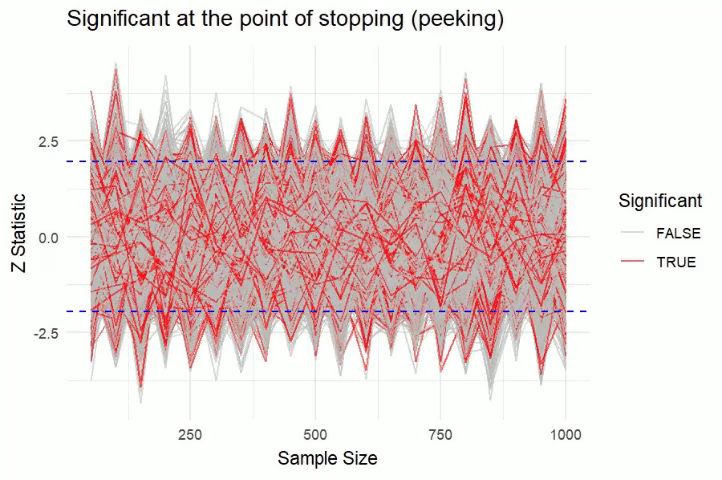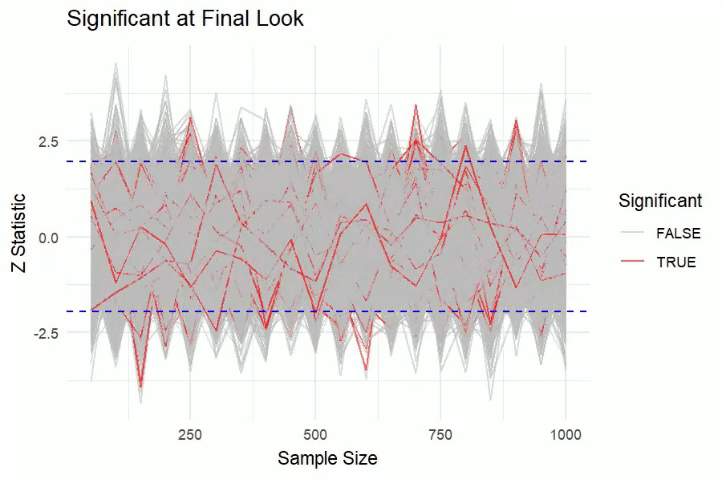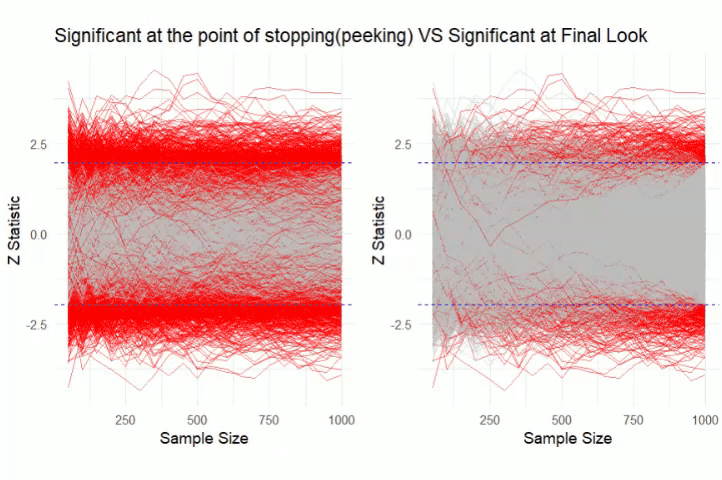
But once the experiments are observed at the end, very few experiments have statistically significant results !!
Avoiding Peeking
Methods like Sequential Testing & Data Blinding help, but will cover them in future posts.
Does Peeking happen in MMM?
Yes it can.
Some marketers suggest calibrating MMM models through experiments. We have written a comprehensive research paper on why this should not be done.
Calibrating MMM models through experimentation is a form of peeking.
Here is how:
Pre mature campaign evaluation
In MMM, there is an assumption that the campaigns that has been on for the historical time period in consideration, will be on in the near future as well. For e.g. a brand might have invested in TV or TikTok or Meta ads and might continue to do so in future. Basically, an end point for these campaigns has not been determined yet.
Now a tweak or stoppage in these campaign spends based on short term experiments may lead to over or underestimating the true effect of the campaigns.
Basically, Marketers may be analyzing the impact of a campaign before it has run its full course.
Frequent Model Calibration
Continuously tweaking (calibrating) the model based on early results from experiments can introduce bias. For example, if a marketer observes that one channel appears to have low ROI early on and adjusts spending accordingly, this could distort the true relationship between that channel and sales.
And since we are in a multi variable set up in MMM, the intricate interactive relationship between other variables also gets affected. This overall might lead to misattribution.
Fracturing the adstock and seasonality
Marketing activities often have lagged effects (e.g., TV ads influencing sales weeks later). Analyzing results too soon may fail to capture these delayed impacts, leading to incorrect conclusions about effectiveness.
Budget Allocation:
If MMM results are reviewed mid-way because of calibration, businesses might reallocate budgets based on incomplete insights, potentially misjudging the long-term effects of certain channels or campaigns.
Overall, it is always better to use experiments to validate MMM or use MMM to validate experiments rather than using experiments to calibrate MMM. Check our Umbra and Penumbra post.
We will be covering all the above topics in more detail in our upcoming MMM Advance course starting March 4th.
Interesting and Related Resources:
https://www.analytics-toolkit.com/glossary/peeking/
https://www.kameleoon.com/blog/ronny-kohavi-getting-results-you-trust
https://engineering.atspotify.com/2023/07/bringing-sequential-testing-to-experiments-with-longitudinal-data-part-1-the-peeking-problem-2-0/
https://www.geteppo.com/blog/peeking-problem-for-product-managers
https://www.geteppo.com/blog/the-bet-test-problems-in-bayesian-ab-test-analysis
https://dl.acm.org/doi/abs/10.1145/3097983.3097992
https://www.lucidchart.com/blog/the-fatal-flaw-of-ab-tests-peeking
https://drive.google.com/file/d/1HrgxFmlngZBb2uOXhbh7WN6NfjFM4FHy/view
Thanks for reading.
For consulting and help with MMM implementation, Click here