



Hits and Misses of Meridian - A Thorough Deep Dive
Good Accurate Google Data + Bayesian MMM = Inaccurate Marketing Measurement


Hello Folks,
So the marketing measurement community is all abuzz again courtesy Google's release of Meridian.
Meridian is the open source Marketing Mix Modeling (MMM) library from Google.
Before we get to the hits and misses of Meridian, I would like to congratulate the Meridian team. Our statistical views could be polar opposite (we preferring Frequentist methods while they prefer Bayesian), however from a software engineering point of view, what Meridian team has achieved is no easy feat.
So Congrats team Meridian !!
We at Aryma Labs completely reviewed the meridian documentation and also ran their demo code.
So lets get down to it.
The Hits
MMM is a Causal Inference Problem

Meridian in its documentation highlights that MMM is a causal problem. This is a step in the right direction. Many think that MMM is equivalent of a typical ML Project where one just plugs in the data, hyper parameter tunes the model to get desired accuracy on the training and test set based on some objective function and then puts the model into production.
MMM involves thinking and most importantly it makes the analyst think about causality. When we say “X dollar increase in TV results in Y dollar increase in sales”, we are implicitly making a causal claim.
However a slight point of disagreement we have in the Meridian documentation is the usage “Bayesian Causal Inference”. Statistically there is nothing as such as Bayesian Causal Inference. Causal inference can’t be colored as Frequentist or Bayesian.
This little Bayesian marketing puffery can be avoided :) It just lowers the credibility of Bayesian methods.
Coming back to the topic of MMM as causal problem, causality analysis can’t be fully automated as it involves analyzing and thinking at every step. This is also why MMM can’t be fully automated.
The Reach Frequency Data Integrations
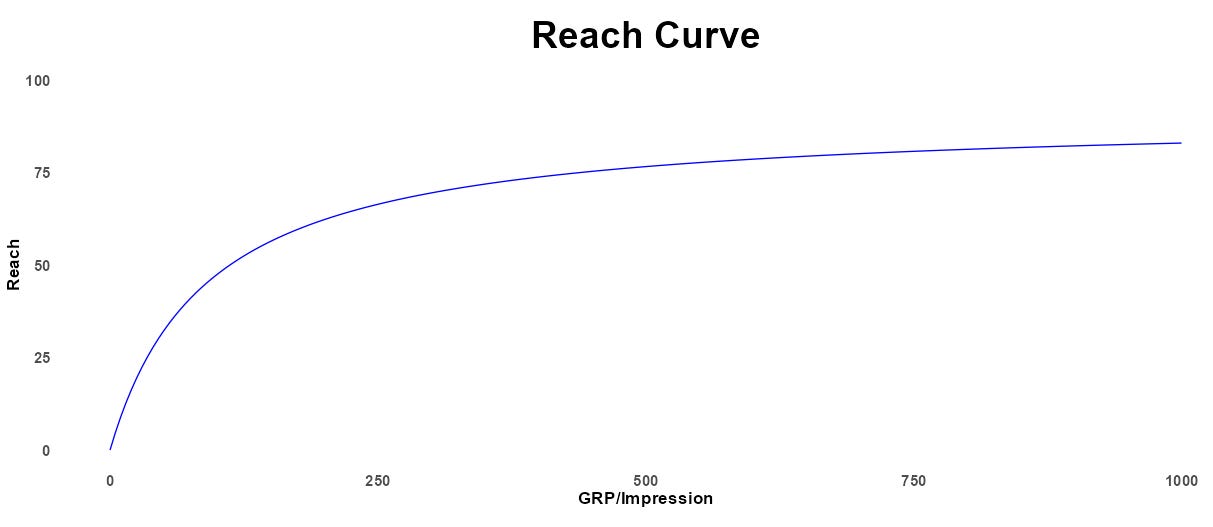
Again, this is a great move by Meridian to make available reach and frequency data as model inputs. This could particularly come in handy in YouTube’s effectiveness measurement. However we remain skeptical of the use of Bayesian Hierarchical Models and believe this could really hamper accurate marketing effectiveness measurement.
The Google Query Volume (GQV)
Google has access to one of the most accurate query/keywords data. If you are including paid search in your MMM model, GQV indeed can act as a good control variable.
Google’s explanation on GQV is spot on “Google Query Volume (GQV) is often an important confounder between media and sales. This is particularly true for paid search because query volume can drive ad volume under certain campaign settings, such as when the budget cap does not prevent it. When GQV is a confounder, you must control for it to get unbiased causal estimates for any media it confounds with. Failing to control for GQV can lead to overestimation of the causal effect of paid search.”
Cautionary Warnings !!
The other positive thing we found in Meridian’s documentation is the ample number of cautions. However how many do read the documentation ? Some of the cautions highlighted in the documentation, be it use of priors, calibrating MMM with experimentation or the problem of same posterior as priors are in fact the ‘Misses’ of Meridian which we will see shortly.
The Misses
Why GPUs?

MMM is actually a multi linear regression with few more bells and whistles like addition of Adstock, accounting for interaction effects and of course trying to control for variables (the causal aspect).
Historically speaking, Linear Regression equation have never been compute intensive. For those of you who have taken a undergraduate Statistics course say 15 years or earlier, you must have fit a simple linear regression on a scientific calculator !!
Yes, simple linear regression is that less compute intensive.

So how did we get from regression on scientific calculators to linear regression on GPUs?
Quite clearly we seem to be doing some thing wrong. Even the LLM world is now singing the 'less is more' motto as Deepseek has demonstrated superior performance on lesser number of compute resources.
The internet is replete with funny examples like below :)
The culprit in the case of Regression on GPUs is none other than Bayesian Methodology.
While a very simplistic 'you can change your belief based on new evidence' is sold by Bayesians, the real implementation of Bayesian methods on any real life problem is very complex. Till date no mission critical domains apply Bayesian methods. The reason for that is not just compute but the convoluted and inaccurate methodology itself (but that is a topic for a different day and that post will take the shape of a book !!).
In fact Bayesian methods overcomplicate things. Some Bayesians even follow the motto 'If you can't convince, confuse'. :)

Anytime you ask some pointed questions to Bayesians like 'what is the rationale behind your choice of prior distribution' or 'What about probability convolutions handling' or 'Why are Bayesian methods unfalsifiable' ?
You are immediately met with disdain and you are accused of not ‘understanding’ Bayesian methods or funnily they will also bring up a 'Not this type of Bayesian' argument.
Apparently there are 100 types of Bayesian methods.
But back to our story of MMMs on GPUs, simple parameter estimation should not require GPUs. In the Bayesian MMM, GPUs are required because of posterior sampling.
The whole Bayesian model fitting is fraught with complexity masquerading to be simple and intuitive.
The Priors
Every Bayesian would proclaim that usage of priors aka ‘encoding prior' knowledge’ is the USP of Bayesian Methods.
However defining prior distribution accurately is tough task even for seasoned statisticians.
Further the choice of prior always falls under scrutiny. No Bayesian modeler can scientifically defend their choice of prior.

In MMM, it is almost always a case of convenience. Since Media ROIs and contributions can’t be negative, Bayesians forcefully curtail it by using either half normal or log normal distribution. But does the variable in question really follow these distributions? You guessed it, absolutely not.

The prior is where everything starts to go wrong. Be it MMM or Experimentation or any other modeling process.
The Same Prior, Same Posterior Problem
Meridian in its documentation does touch upon this problem.

However it brushes past the real reason of the problem - The Bayesian Method itself.
MMM is inherently a small data problem. Given the ‘smallness’ of the data, the priors almost always overwhelm the data (likelihood) and you end up having the prior as your posterior !!

So this actually provides a loophole to MMM vendors.
Bayesian MMM is more prone to manipulations than Frequentist MMM precisely for the above reason.
If a MMM vendor somehow knew that a higher ROI on a particular media channel would make the client happy, all he /she has to do is, set a very high ROI as prior !!

Overestimating Contribution Numbers and ROIs Courtesy Log Normal Prior
The problem of priors is not over yet. Meridian uses log normal as a default prior. But the trouble starts when it uses Mean of Log normal in the posterior as opposed to the HDI (Highest Density interval).
The problem with using mean in log normal is that it is almost always higher than median, mode and in most cases the HDI as well.
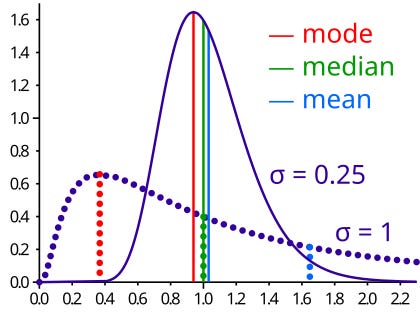
So we end up in a scenario where we are overestimating the ROI of a marketing channel !
Perhaps it is a small fix for meridian where they would have to implement HDI as the posterior number as opposed to the mean. But in its current set up, Meridian runs the risk of overestimating the contribution and ROIs of media channels.
This also means that the meridian runs the risk of underestimating Base or Brand Equity always if it used mean of log normal.
The Multicollinearity Problem
Multicollinearity is one of the biggest Achilles heel of MMM. However it is a bigger problem for Bayesian MMM.
Even under moderate multicollinearity, the posterior distribution gets inflated.

While the multicollinearity is not a flaw of meridian, but meridian using Bayesian MMM kind of makes it inherit this flaw.
In MMM, accurate attribution is everything. Multicollinearity hampers this accurate attribution.
Using Experiments to Calibrate MMM
We mentioned that one of the positives of Meridian is its cautionary warnings in the documentation.
Meridian does slightly hint to users that using experiments to calibrate MMM may not be an accurate approach.

Meridian seems to be making the same mistake as Robyn.
MMMs can’t be calibrated through experiments.
We have written a comprehensive research paper ‘Why you should not calibrate MMM models through experiments’ where we empirically demonstrate that using experiments to calibrate MMM models, makes the MMM model worse on almost all calibration metrics !!
However a TL;DR version is :
1) The temporal component mismatch
MMM's are generally built on a dataset that spans many months/ years. Marketing activities have long-term, delayed effects that accumulate
over time. MMM captures these effects.
Experiments on the other hand are carried on for short span of time - few weeks or 1-2 months. Therefore they don't capture the long-term effects.
Using experimental results, which often do not account for these complex interactions and time dependencies, to adjust MMM model parameters has the possibility to introduce biases and severely cripple MMM model's accuracy.
Hence, using experiment results to make changes to MMM hence would be in an essence polluting the MMM.
2) MMM models conditional dependencies while experiments do not
In a typical linear regression, we model the conditional expectation E[Y|Xi]; where Xis are your independent variables.
So in MMM, the predicted sales that you got from model is actually conditioned upon all your marketing variables and even external factors like seasonality, economic factors.
Experiments on the other hand are univariate in nature and provides you
marginal effect that is not conditioned upon other marketing variables. Therefore using experiment results to make changes in MMM does not make sense at all.
We will soon be adding a addendum to the paper where we will also show the same results through Meridian data.
We at Aryma Labs believe that Experiments can be used to validate MMM (there is a difference between calibration and validation) and at the same time MMM can be used to calibrate experiments (post on this coming soon).
The Final Takeaway
While open source MMM libraries like Robyn and Meridian help democratize MMM, they miss a lot of crucial details. And most certainly they are not Free. There are hidden costs of open source MMM libraries.
Google arguably has some of the best and accurate data at hand. However its choice of using Bayesian MMM in Meridian could derail its mission of accurate Marketing Measurement.

Given that there is no dearth of bright minds in Google, perhaps a Frequentist flavor of Meridian would immensely benefit Google and the larger Marketing Measurement Community as well.
For a technical overview of Meridian, pls check this link : https://github.com/Venkatstatistics/Meridian-Technical-Overview.git
Thanks for reading.
For consulting and help with MMM implementation, Click here