

Difference-in-Differences (DiD) vs Synthetic Control Method (SCM) : Why Staying Closer to Reality Matters
DiD always outperforms SCM because nothing can come close to reality


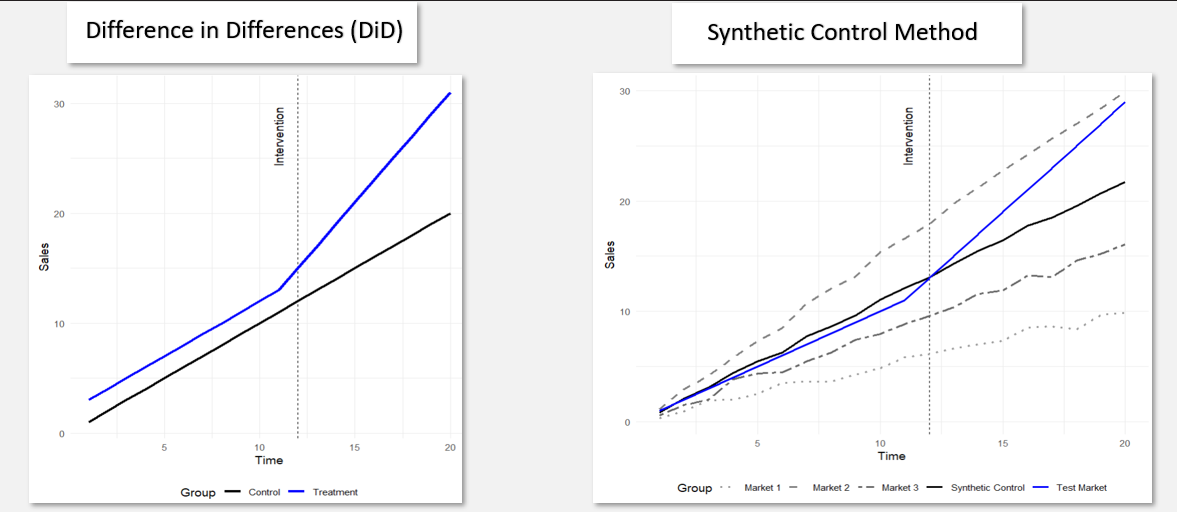
Recently I came across a great explanation of Synthetic Control Method (SCM). But there was one line that I couldn’t agree with:
“This synthetic version matches your real unit’s trends perfectly before the intervention.”
No control unit real or synthetic will ever perfectly match a treated unit. The word perfect is misleading. But a real control unit is any day better than a synthetic one and because of this, DiD will always be more accurate than SCM.
Let me elaborate my rationale:
Models are abstractions of reality
Every mathematical model is already an abstraction. A simplified lens on reality with inherent errors.
With DiD, the abstraction is one level away from reality: you compare your treated unit to a REAL control unit under the parallel trends assumption.
With SCM, you create a synthetic control by estimating weights across multiple units. This is an abstraction on top of an abstraction. Errors hence compound and the model is now two steps removed from reality.
Intuitively, the closer you are to reality, the higher your chance of accuracy.
SCM almost always overfits
SCM’s reliance on optimization e.g. weights like [0.7, 0.2, 0.1] introduces estimation error and often overfits pre-treatment trends, leading to divergence post-treatment. This divergence may give indication of causality but don't be fooled. Further without a real control as reference, you don’t know how far off you are !!
In contrast, DiD doesn’t 'solve for weights'. It directly uses the best real control.
False equivalences and complexity ≠ accuracy
Some argue both DiD and SCM can be written as convex optimization problems. But that is a false equivalence.
For DiD, you don’t need to solve one. Because you have the real unit in first place.
For SCM, you must, and every step of estimation introduces more error.
More Estimation = More Error and More Error = Less Accuracy.
More Estimation = More Error and More Error = Less Accuracy.
Thought Experiment - 3 control markets
Suppose we have three control markets [A, B, C]
DiD identifies A as the real control.
SCM may also identify A, but may assigns weights like [0.7, 0.2, 0.1]
Now your synthetic control is unnecessarily polluted by B and C, reducing accuracy.
This is the true test for SCM. When a real control exists, what weightage does it give it?
The true test for SCM is → When a real control exists, What weightage does it give it?
Causal interpretation matters
DiD offers a clear causal interpretation under its assumption. SCM’s weighted mixtures like 85% unit A, 5% unit B and 10% C are optimization artifacts and often not reflections of real economic or marketing units.
This is why DiD’s assumptions are ultimately more reasonable and its estimates more robust in practice.
In summary:
Both methods are valuable in the causal inference toolkit. But when the goal is accurate business decision making and not just academic elegance, the hierarchy is clear:
DiD > SCM.
Talking about DiD: We have developed a robust DiD tool called DiDective:
Sign up : https://did.arymalabs.com/accounts/login/
About DiDective: https://arymalabs.com/didective/
A demo of it on real data:
Thanks for reading.
For help with Causal Marketing Experiments and MMM, get in touch with us.
 | A guest post by
|